Importing data into Firestore using Python Part 2: Data Types

After publishing a guide to importing data into Firestore using Python, I recieved a few questions which I thought I'd start to address with further guides. In this one how to import data with types from a csv.
Guide to importing data
In my previous guide I demonstrated a way to take data from csv files and import them into firestore, to briefly recap:
Generating Service Account Key
To use the SDK we’ll need to have a Service Account Key. You can generate this by using Firebase Console > Project Settings:
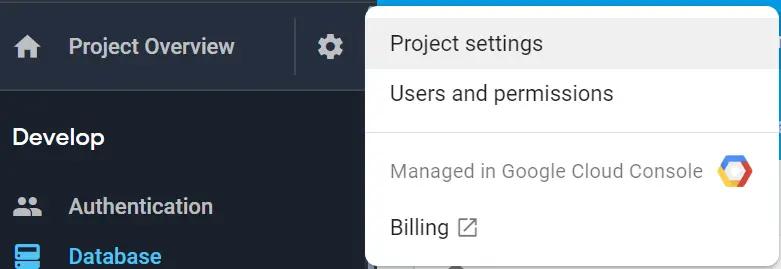
Then selecting Service accounts and clicking Generate new private key:
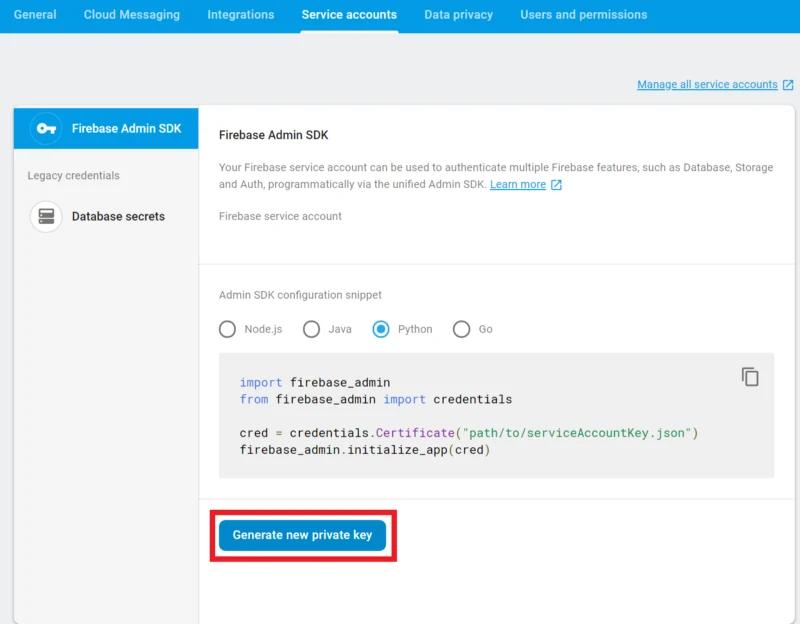
This will produce a .json file with the credentials needed to access the Firebase project.
IMPORTANT! Keep this confidential, don’t add it to version control or to a client side application.
Set up a python project with the following dependencies:
pip install firebase-admin google-cloud-firestoreand the following main.py
import csv
import firebase_admin
import google.cloud
from firebase_admin import credentials, firestore
cred = credentials.Certificate("./ServiceAccountKey.json")
app = firebase_admin.initialize_app(cred)
store = firestore.client()
file_path = "CSV_FILE_PATH"
collection_name = "COLLECTION_TO_ADD_TO"
def batch_data(iterable, n=1):
l = len(iterable)
for ndx in range(0, l, n):
yield iterable[ndx:min(ndx + n, l)]
data = []
headers = []
with open(file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
line_count = 0
for row in csv_reader:
if line_count == 0:
for header in row:
headers.append(header)
line_count += 1
else:
obj = {}
for idx, item in enumerate(row):
obj[headers[idx]] = item
data.append(obj)
line_count += 1
print(f'Processed {line_count} lines.')
for batched_data in batch_data(data, 499):
batch = store.batch()
for data_item in batched_data:
doc_ref = store.collection(collection_name).document()
batch.set(doc_ref, data_item)
batch.commit()
print('Done')Importing data with types
In order to import data with types the simplest way is to add an additional row which defines these types to the csv file:
test,item,pass
string,int,bool
test1,1,TRUE
test2,2,FALSESo the format becomes header, types and then data rows.
Then add an additional function to convert the data to the appropiate type.
def get_data_item(item, data_type):
# Add other data types you want to handle here
if data_type == 'int':
return int(item)
elif data_type == 'bool':
return bool(item)
else:
return itemAnd update the script to utilise this:
import csv
import firebase_admin
import google.cloud
from firebase_admin import credentials, firestore
cred = credentials.Certificate("./ServiceAccountKey.json")
app = firebase_admin.initialize_app(cred)
store = firestore.client()
file_path = "CSV_FILE_PATH"
collection_name = "COLLECTION_TO_ADD_TO"
def batch_data(iterable, n=1):
l = len(iterable)
for ndx in range(0, l, n):
yield iterable[ndx:min(ndx + n, l)]
def get_data_item(item, data_type):
# Add other data types you want to handle here
if data_type == 'int':
return int(item)
elif data_type == 'bool':
return bool(item)
else:
return item
data = []
headers = []
data_types = []
with open(file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
line_count = 0
for row in csv_reader:
if line_count == 0:
for header in row:
headers.append(header)
line_count += 1
elif line_count == 1:
for data_type in row:
data_types.append(data_type)
line_count += 1
else:
obj = {}
for idx, item in enumerate(row):
obj[headers[idx]] = get_data_item(item, data_types[idx])
data.append(obj)
line_count += 1
print(f'Processed {line_count} lines.')
for batched_data in batch_data(data, 499):
batch = store.batch()
for data_item in batched_data:
doc_ref = store.collection(collection_name).document()
batch.set(doc_ref, data_item)
batch.commit()
print('Done')As it is an object you are inserting into Firestore the types are also transferred:
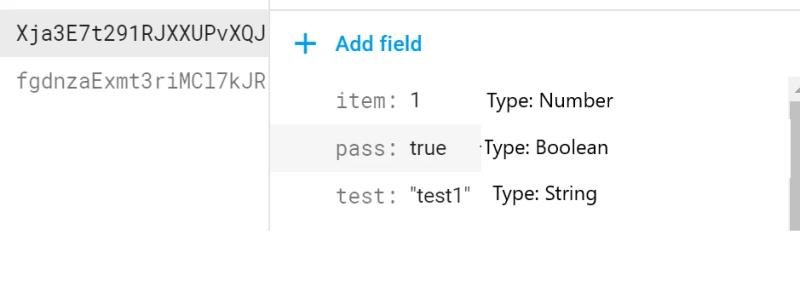
Add additional data types into the function as required and you are then able to create typed data inserts.
- Firebase
- Firestore
- Python